



As data scientists or engineers, manipulating string data with regular expressions in Pandas is a vital skill to have. Typical chores with regular expressions include splitting text, removing accents, and cleaning out unwanted characters. One of the most common tasks is to extract words of interest (keywords) from the columns, known as Keyword Extraction.
Keyword Extraction has various applications, such as categorizing content, summarizing text, analyzing social media sentiment, conducting market research, and identifying content themes. It is a valuable tool for gaining insights from large amounts of text data.
Most online suggestions for using regular expressions to extract keywords propose a solution that is easy to implement but suffer from slow performance, making them less suitable for processing large datasets.
This article will show how you can use trrex, a python library that creates a regular expression pattern hundreds of times faster than the most common solution. You don't necessarily need to be an expert in Python or regular expressions to benefit from this tutorial, but it would be helpful to have some familiarity with them.
TL;DR
If you're looking for a way to accelerate keyword extraction with regular expressions, just check the trrex documentation.
If you find the project useful, please consider giving the repository a star. This simple action can assist others in discovering the tool as well.
The Problem
The Keyword Extraction problem can be seen as a variation of the string matching problem. It involves identifying one or more specified patterns within a larger text or string. In the context of Python and Pandas, this means extracting all matching keywords from a string column in a Pandas DataFrame and placing them in a new column of type list.
So for the following DataFrame df and list of keywords (strings) emotions :
import pandas as pd
df = pd.DataFrame({
'opinions': [
"The acting was terrible, I wouldn't recommend it to anyone.",
"I loved the cinematography, but the plot was confusing.",
"I don't know why people like this movie, it was awful.",
"I laughed so hard during the movie, it was hilarious!",
"I found the movie to be quite amazing. I had a great time!",
"I can't wait to see it again, it was very lovable!",
]
})
emotions = ['terrible', 'awful', 'loved', 'lovable', 'great', 'hilarious', 'lacking', 'amazing']
The expected output is:
opinions emotions
0 The acting was terrible, I wouldn't recommend ... [terrible]
1 I loved the cinematography, but the plot was c... [loved]
2 I don't know why people like this movie, it wa... [awful]
3 I laughed so hard during the movie, it was hil... [hilarious]
4 I found the movie to be quite amazing. I had a... [amazing, great]
5 I can't wait to see it again, it was very lova... [lovable]
Solution 1: Using the | operator, a.k.a common solution
The straightforward approach and most common solution for solving this problem, using regular expressions, is to do the following:
query = '|'.join(emotions)
df['emotions'] = df['opinions'].str.findall(rf'\b({query})\b')
The | is the alternation or the "or" operator, from the Python documentation:
If A and B are regular expressions,
A|Bwill match any string that matches either A or B.|has very low precedence in order to make it work reasonably when you’re alternating multi-character strings.Crow|Servowill match either'Crow'or'Servo', not'Cro', a'w'or an'S', and'ervo'.
The \b is a word boundary that matches the empty string at the beginning or end of a word (where a "word" is defined as a sequence of characters consisting of letters, digits, or underscores). It ensures that the regular expression only matches whole words rather than parts of words.
For our toy example, the pattern would be something like this:
"\b(terrible|awful|loved|lovable|great|hilarious|lacking|amazing)\b"
This regular expression pattern, while simple to create, is very inefficient. For each pipe-separated option, the regular expression engine has to backtrack and try a different option if the current one doesn't match. This can be very inefficient, especially if there are many pipe-separated options or if the options are long and complex.
Solution 2: Using Trrex
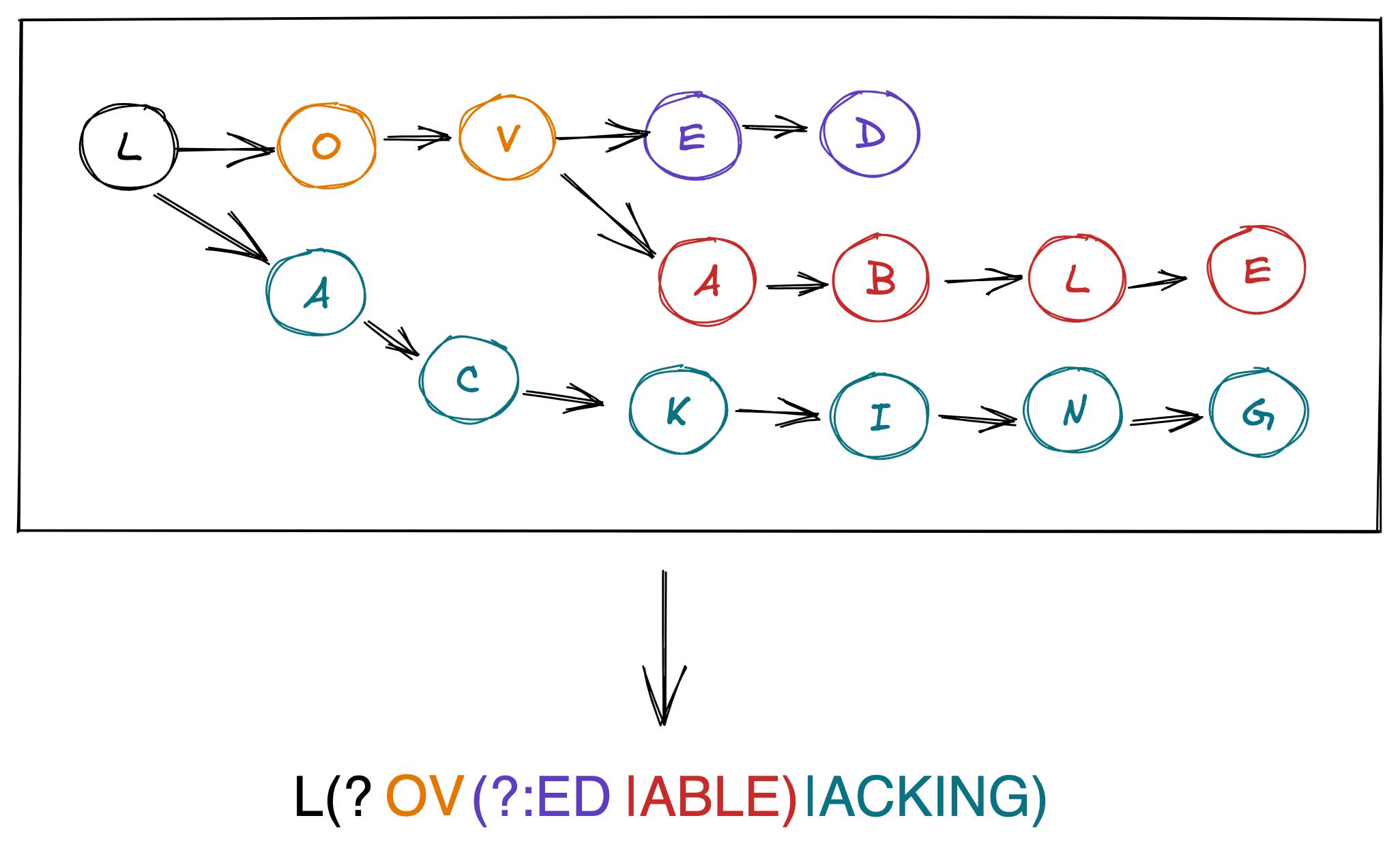
Trrex is a library with a pure Python function that enables you to represent the set of keywords as an efficient regular expression. It first builds a TRie (see here) and then constructs a REgular eXpression, hence the package's name. For instance, the words "loved", "lovable", and "lacking" would generate a trie and pattern like the one in the image below:
To use trrex, first make sure to install it:
pip install trrex
Then import the library and use the make function:
import trrex as tx
query = tx.make(emotions, prefix=r"\b(", suffix=r")\b")
df['emotions'] = df['opinions'].str.findall(query)
The final pattern made by trrex looks something like this:
"\b((?:terrible|l(?:ov(?:ed|able)|acking)|hilarious|great|a(?:wful|mazing)))\b"
The advantage of a trie-based regular expression, like the above one, is that it can efficiently handle common prefixes and reduce backtracking. By constructing a trie of all possible prefixes of the regular expression, the trie can match common prefixes of multiple alternatives without backtracking.
For example, consider the regular expression ab|ac|ad. In this case, the regular expression engine would have to try each alternative sequentially and backtrack if the current alternative didn't match. However, with a trie-based regular expression like a(b|c|d), the regular expression engine can use the common prefix a to eliminate options that do not match quickly.
Benchmark
To compare the speed advantages of a trie-based regular expression versus a generic pipe-based one, we generated a DataFrame with a single string column (10,000 Jeopardy questions) and a set of 75,000 English words (the keywords). For each experiment run, we randomly selected a subset of keywords (as determined by the count parameter), ensuring that at least one keyword matched each Jeopardy question by inserting a word from the random sample. The timings for each experiment run are displayed in the accompanying graph. The code for reproducing the benchmark can be found here.
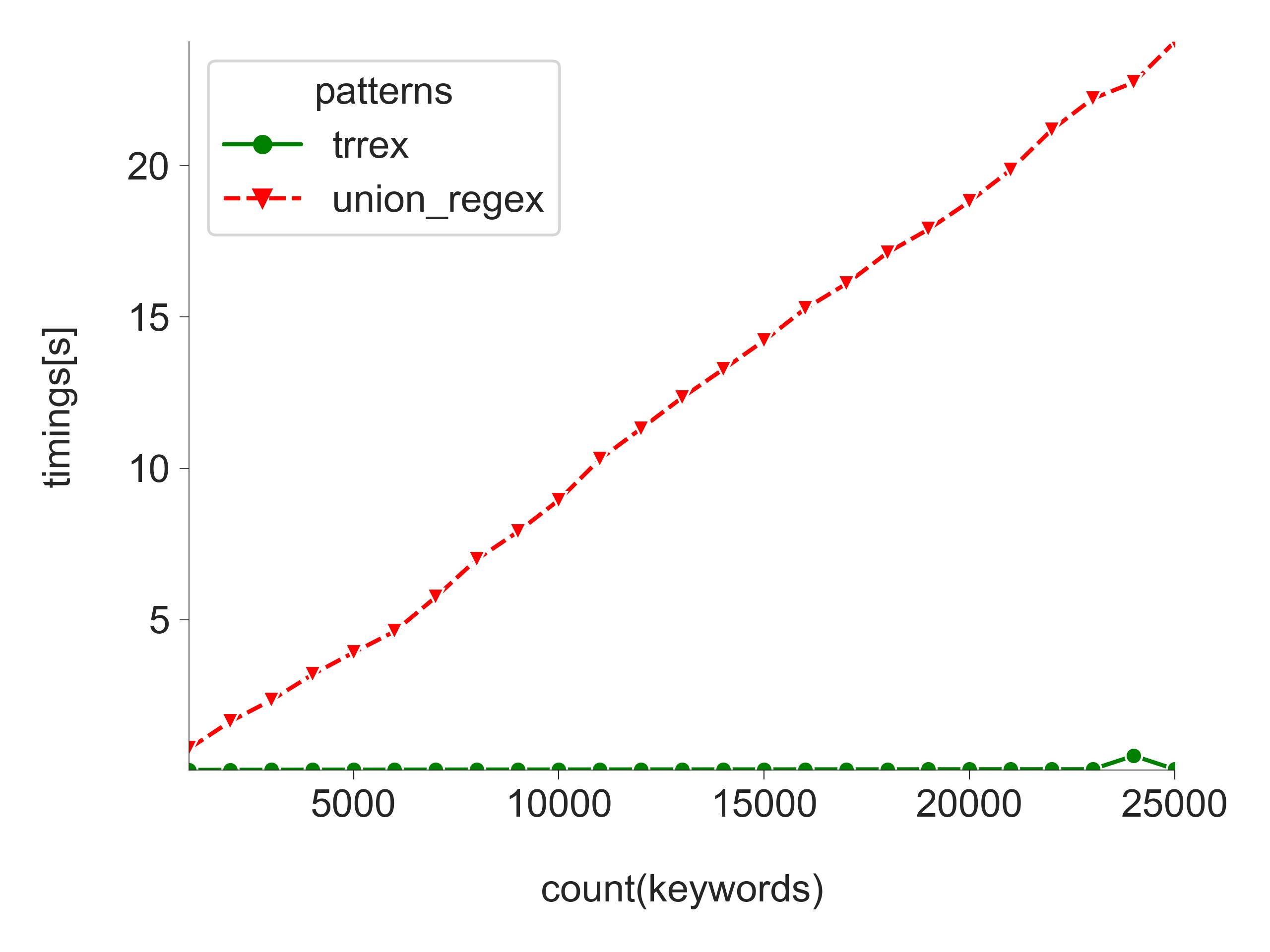
When comparing a count of 25,000 keywords, the speed gain of using a trie-based regular expression was an impressive 400 times faster than using a pipe-based one (24 seconds for pipe-based vs. 0.06 seconds). It's worth noting, however, that for a count of 24,000 keywords, the speed gain was "only" 46 times faster (22 seconds for pipe-based vs. 0.5 seconds for trie-based). The number of common prefixes between the keywords influences this difference in performance. If there are no shared prefixes, the performance of the trie-based regular expression will be equivalent to the pipe-based one. Nonetheless, these results highlight the significant benefits of using a trie-based regular expression for efficient keyword extraction.
Conclusion
In conclusion, this article has demonstrated the ease of use and remarkable performance gains of using trrex for keyword extraction. It is ideal for this task and can also be used for keyword replacement, fuzzy matching, pattern matching, and other similar purposes. Additionally, as the documentation showcases, trrex can integrate seamlessly with pandas, spacy, and other regex engines.
So, if you find trrex helpful, please consider giving the repository a star to help others discover this invaluable tool.
Acknowledgments & Disclaimer
The trrex library is based on the fantastic article: Speed up millions of regex replacements in Python 3 from StackOverflow. I'm also the author of trrex.